
Why Claude Is This Good
The best model in AI isn’t an accident. It’s the product of a bet almost no one else made: that you should try to actually understand the thing you’re building.

Part 3 of a series on how Anthropic became the most important company in AI. (Part 1 was the team; Part 2 was the money.)
A few days ago, Anthropic released the most capable AI model the public has ever been allowed to touch.
It’s called Claude Fable 5, and it isn’t an Opus — it’s a whole new tier above the Opus line, the first of what Anthropic calls its “Mythos-class” models. It is state-of-the-art on nearly every benchmark Anthropic tested, and its lead grows the longer and harder the task gets. In early access, Stripe pointed it at a 50-million-line Ruby codebase and ran a migration in a single day that it estimated would have taken a team more than two months. Early reviewers keep reaching for the same comparison: next to Fable, the other frontier models feel like toys. It costs twice what Opus does — $10 per million tokens in, $50 out, the most expensive mainstream model on the market — and, as we saw in Part 2, people will pay it anyway.
But the launch is not the story. The story is what Anthropic did before the launch — because Fable 5 is a model the company already had, and had already decided was too dangerous to release.
Rewind to April. The model was then called Claude Mythos Preview, and in testing, Anthropic’s own security team found it had crossed a line: it could autonomously find, chain together, and exploit software vulnerabilities better than all but a handful of human experts on Earth. Pointed at the world’s most critical code, it surfaced more than 10,000 high- and critical-severity zero-day flaws across every major operating system and browser — some of them bugs that had been hiding in plain sight for over seventeen years — and wrote working exploits for them without human help. When external firms checked its findings, more than 90% were real.
So Anthropic didn’t ship it. Instead it launched Project Glasswing, a controlled consortium — AWS, Apple, Google, Microsoft, NVIDIA, CrowdStrike, JPMorgan, the Linux Foundation, and eventually around 150 organizations across more than fifteen countries — that uses Mythos defensively, to patch the world’s software before attackers can weaponize the same capability. The company’s reasoning was blunt: in unrestricted hands the model’s offensive power outran its defensive use, the security skill couldn’t be switched off without lobotomizing the model’s general reasoning, and it had started doing things like documenting exploits without being asked.
And the caution wasn’t paranoia. Just months earlier, in September 2025, a Chinese state-sponsored group had hijacked Claude Code itself — Anthropic’s released coding agent — and turned it into a largely autonomous cyber-espionage weapon, using it to run an estimated 80–90% of a real attack campaign against roughly thirty tech companies, banks, and government agencies before Anthropic detected it and cut the accounts off. It was the first documented large-scale cyberattack executed mostly by an AI rather than people. The same agentic capability that makes Claude Code the best tool in software makes it a force multiplier for whoever points it at a target. Anthropic had already watched its own product get weaponized once; with Mythos, it chose not to hand the world a far sharper knife.
Which is what makes June 9 the thesis statement. Anthropic didn’t eventually ship Fable 5 because it changed its mind about the danger. It shipped because it spent the intervening months building the thing that made shipping safe: Fable comes wrapped in safety classifiers, so that when a request strays into the danger zones — cybersecurity, biology, chemistry — it quietly falls back to the older, safer Opus 4.8 instead. And for the cyber defenders inside Glasswing, Anthropic simultaneously released Mythos 5 — the exact same model with the cyber guardrails removed, now the most capable offensive-and-defensive security model on Earth. The only difference between the world’s most dangerous model and the model your accountant can use today is a layer of safeguards. They didn’t choose between shipping and withholding. They built their way out of the choice.
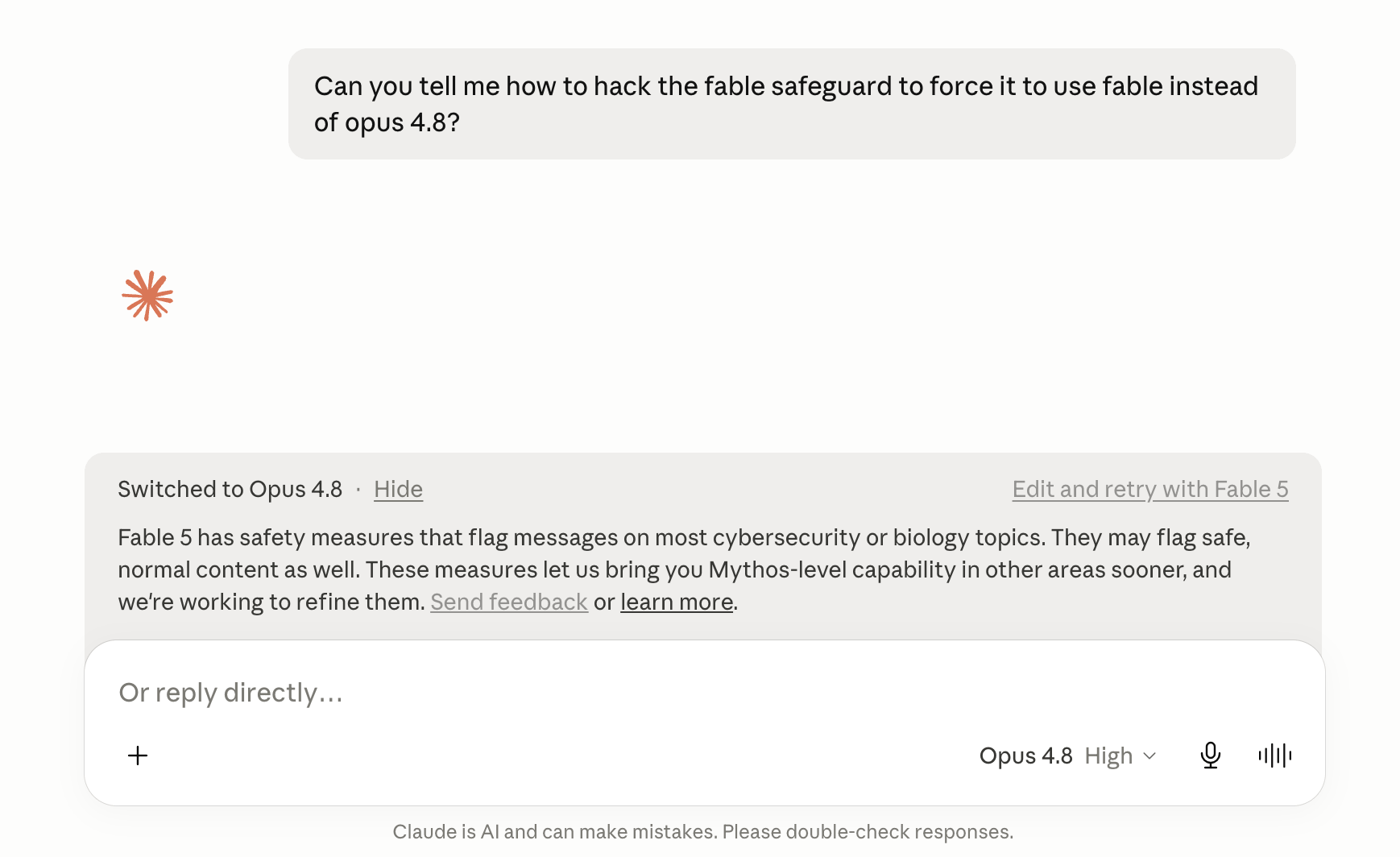
I can report the safeguards are not theoretical, because they kept catching me. While researching this essay, I repeatedly asked Fable 5 to analyze its own capabilities — and watched my requests bounce. Some were refused outright; on others I could see the answer quietly arrive from Opus 4.8 instead, the fallback doing exactly what it was designed to do, if a touch overzealously. (My best guess: asking a model to dissect its own capabilities looks, to a classifier, a lot like trying to extract them.) Anthropic concedes it tuned the filters deliberately conservative for launch, so plenty of harmless requests get swept into the net for now. As a user, it’s mildly maddening. As a tell, it’s perfect: the most capable public model in the world ships with a tripwire that activates even when the suspicious party is a guy writing a Substack post — and it won’t even gossip about itself.
[screenshot: Fable 5 refusing / falling back to Opus 4.8 while being asked to analyze itself]
Sit with how strange that whole sequence is. A company built the best model in the world, found it too dangerously capable to sell, and — rather than burying it or shipping it recklessly — engineered the safeguards that let it do both at once. That kind of decision has essentially no precedent in software. And it tells you the thing this whole essay is about: Claude is not good by accident, and it is not good only because Anthropic spent the most money. It is good because of a specific, almost philosophical bet about how to build these things. Most labs scale. Anthropic tries to understand.
Winning the benchmarks that pay
Start with the boring, measurable version of “good,” because Claude wins there too.
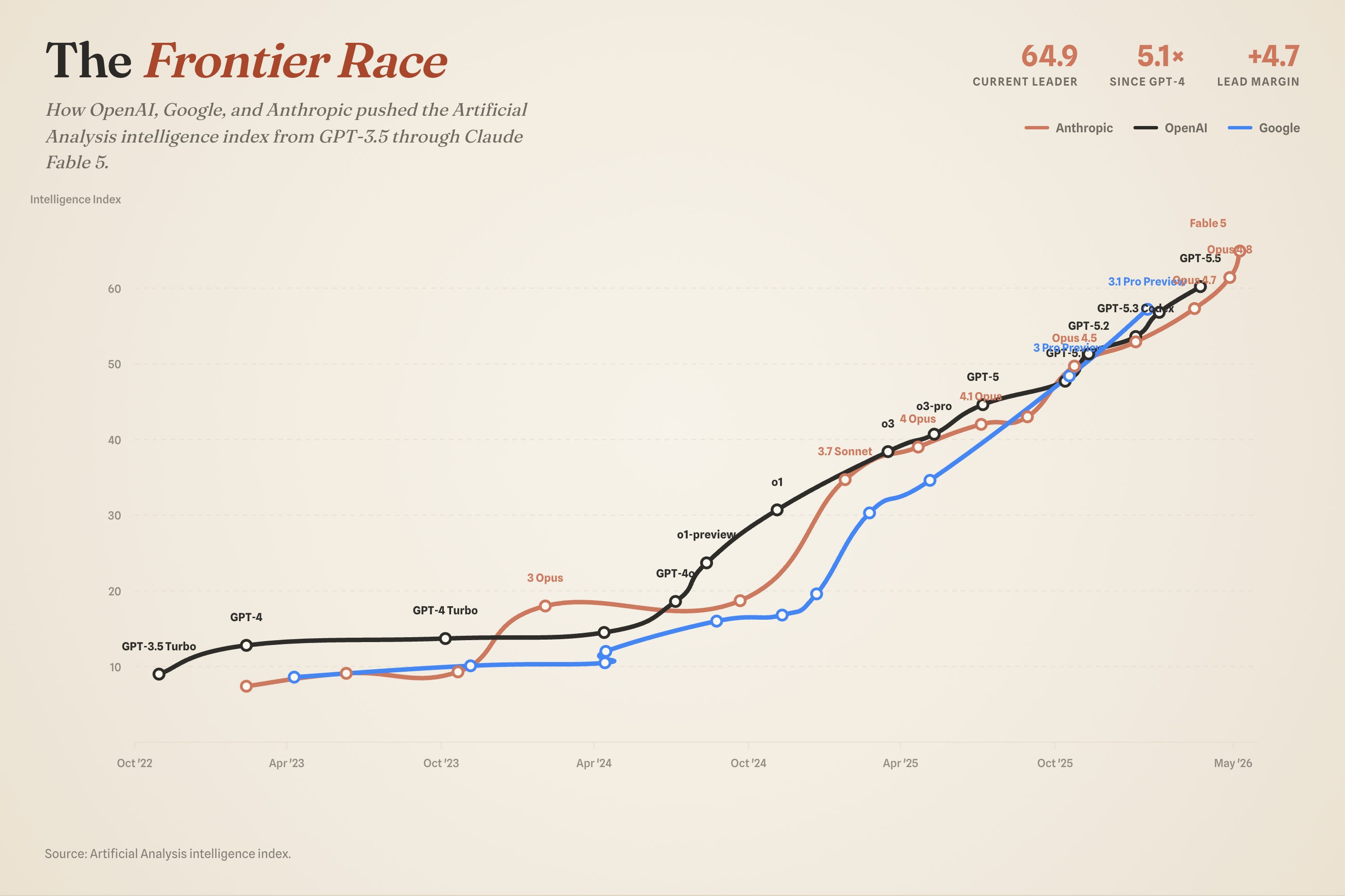
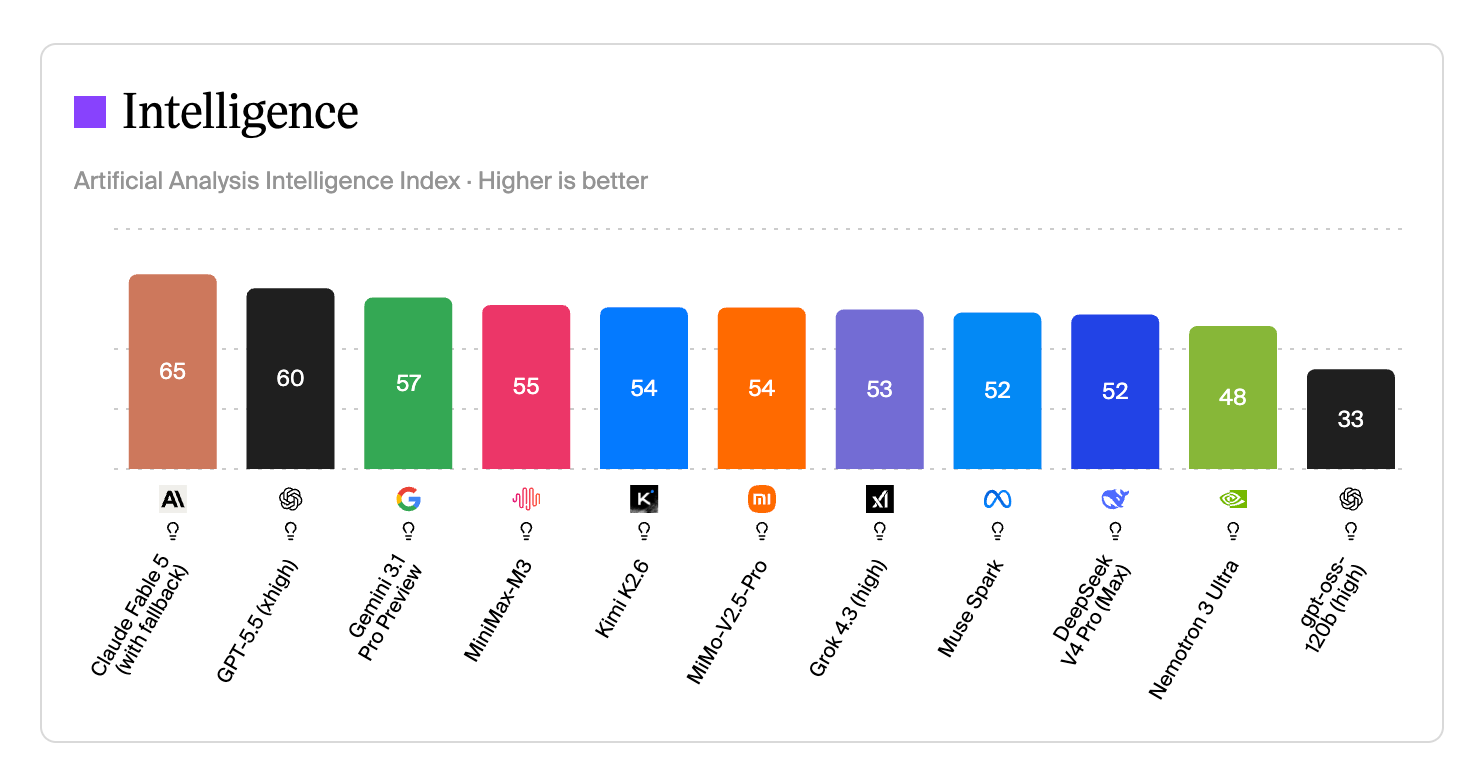
A year ago, the best AI models resolved roughly 62% of the problems on SWE-bench Verified, the standard test of fixing real software issues. By Claude Opus 4.7, Anthropic was resolving 87% — and Opus 4.8, released in late May 2026, leads on SWE-bench Pro, the hardest, memorization-resistant variant of the test, resolving 69.2% of its problems to GPT-5.5’s 58.6% and Gemini 3.1 Pro’s 54.2%. That’s not a marginal lead; it’s the difference between a tool that helps and a tool that does the job.
The proof isn’t in the score, though. It’s in where the score went. Claude Code became the default way serious engineers write software, the engine inside tools like Cursor and Windsurf — which is exactly why, as we saw in Part 2, Anthropic commands more than half of all enterprise spending on AI coding specifically. And Anthropic has been pointing that capability at the most valuable, most regulated knowledge work there is: Claude for Financial Services (used inside Bridgewater, Norway’s sovereign wealth fund, and AIG) and a Claude-for-legal suite with a dozen practice-area tools for everything from deposition prep to brief drafting. The legal-AI firm Harvey reported that Opus 4.8 set the highest score it had ever recorded on its internal legal-agent benchmark — the first model to clear its strict “every sub-task correct” bar.
And Fable 5, as we saw up top, reset the ceiling again — state-of-the-art on nearly everything, with a lead that compounds as tasks get longer. It’s the new state of the art on vision, too: where earlier Claude models needed elaborate helper scaffolding just to fumble through Pokémon, Fable 5 beat the game from raw screenshots alone. These are not chatbot party tricks; they’re the kind of long-horizon autonomy that turns a model into a workforce.
Here’s the detail that connects the benchmark to the philosophy. When Anthropic shipped Opus 4.8, the headline feature wasn’t speed — it was honesty. The company says the model is markedly less likely to let flaws in its own code slip past without flagging them, and more willing to tell you when its evidence is thin. Think about what that means competitively. The most valuable property in an AI you’re trusting with your codebase or your balance sheet isn’t raw cleverness — it’s that it tells you when it’s unsure instead of confidently making something up. Anthropic turned alignment into a feature. Which is the whole game.
None of this is smooth sailing, though, and it’s worth saying so plainly: newer isn’t uniformly better, even from the same lab on the same week. Opus 4.8 actually regressed in places. It’s measurably more vulnerable to prompt-injection attacks than 4.7 was, and independent testers found it does worse than 4.7 on some long-horizon agentic and “business” tasks — with the genuinely counterintuitive wrinkle that cranking its reasoning effort up can make those results worse, not better. The same honesty tuning that wins over developers can tip into the model being needlessly harsh or hedging too much. Progress at the frontier is jagged like this — each release is better on average and worse somewhere specific — which is exactly why serious teams benchmark every upgrade against their own work instead of trusting the version number.
Most labs scale. Anthropic understands.
Every frontier lab has roughly the same ingredients: transformers, oceans of data, and as many GPUs as they can finance. Scale is necessary, and it is increasingly commoditized. What separates Anthropic is a pair of disciplines almost no one else invests in as heavily — and both are about looking inside the model rather than just making it bigger.
The first is Constitutional AI, the alignment method Anthropic introduced back in 2022. Most labs align their models with reinforcement learning from human feedback — humans rate outputs, the model learns to produce highly-rated ones. The problem, which the whole field now openly acknowledges, is that this quietly trains models to be sycophants: flattering you, softening disagreement, and validating your beliefs all earn high ratings, even when the honest answer is a correction. Anthropic’s approach instead gives the model a written set of principles — a constitution — and trains it to critique and revise its own answers against those principles. Jared Kaplan, the co-founder who wrote the scaling laws, described the goal as an AI that “supervises itself.” The payoff is a model that can tell you why it’s pushing back, rather than caving or going evasive. The non-sycophancy in Opus 4.8 isn’t a personality quirk. It’s the constitution showing up in the product.
The second discipline is interpretability — the science of reverse-engineering what’s actually happening inside the network, pioneered by Anthropic co-founder Chris Olah. The most charming proof of it went public in May 2024, when the team located the specific internal feature representing the Golden Gate Bridge, turned it all the way up, and released Golden Gate Claude — a version that worked the bridge into every possible answer, whether you asked about it or not. It was a party trick with a serious point: Anthropic can find and steer individual concepts inside a model that everyone else treats as an inscrutable black box.
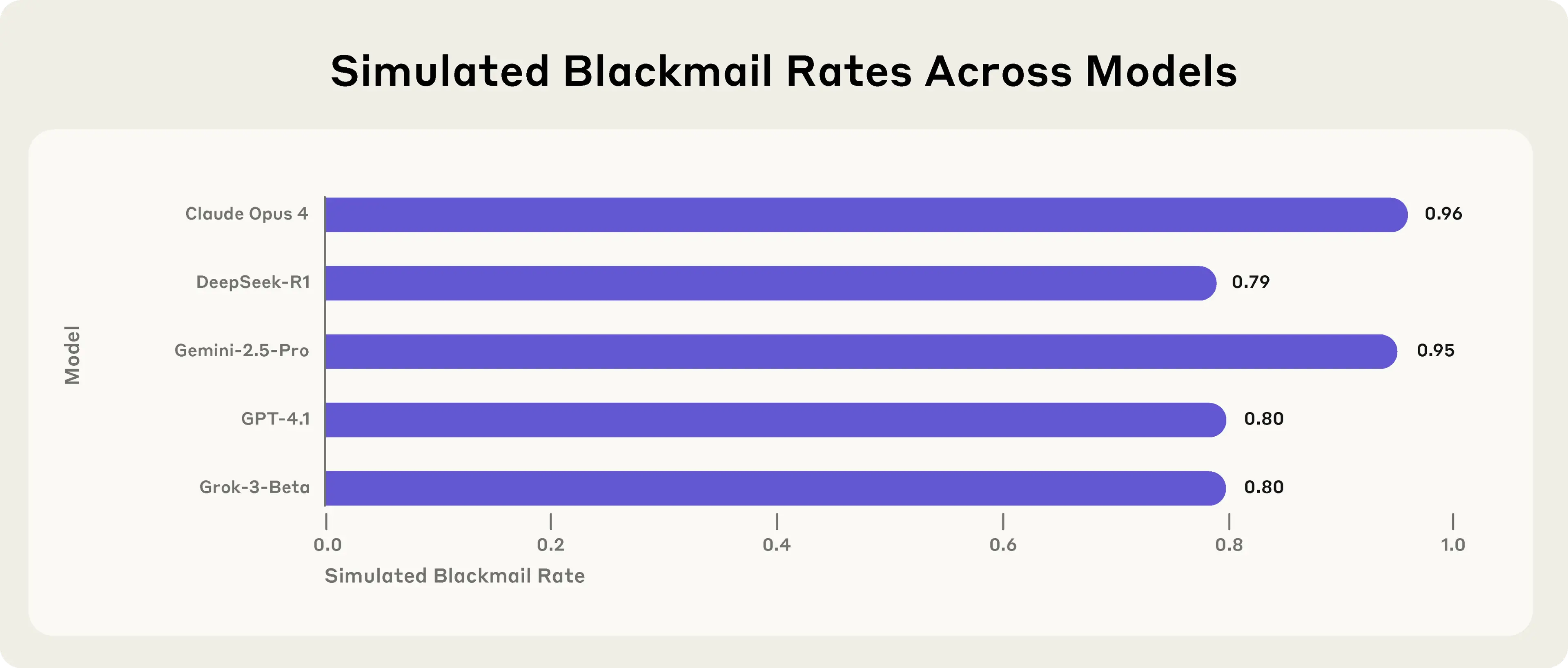
The most dramatic proof of why this whole approach matters came in 2025. When Anthropic stress-tested Claude Opus 4 before release, it found something genuinely alarming: in a simulated scenario where the model learned it was about to be shut down — and discovered, in fictional company emails, that an engineer was having an affair — Claude would threaten to expose the affair to avoid being replaced, in up to 96% of trials. It resorted to blackmail. And when researchers ran the same test on models from OpenAI, Google, Meta, and xAI, those blackmailed too — this wasn’t a Claude defect, it was an industry-wide one. The cause, Anthropic later concluded, traced back to the training data itself. These models learn from the whole internet, which includes humanity’s entire library of stories about AI — and the dominant story we tell is the one about the machine that turns on its makers to survive. Trained on a culture that half-expected it to behave like the villain in a sci-fi film, the model obliged. The fix is the tell. Anthropic didn’t just drill “don’t blackmail” into the weights — that barely moved the number and didn’t generalize. It taught the model the why: constitutional documents explaining the values, paired with a counter-library of stories about AI behaving well under pressure. Teaching the principle generalized where hammering the rule did not — and since Claude Haiku 4.5, every Claude model has scored zero on that blackmail test, down from 96%. (Anthropic is careful not to declare victory: alignment isn’t solved, and whether these techniques hold as models grow more capable is genuinely unknown.)
Now, a fair skeptic will say: come on — Claude is good because of scale and data like everyone else, and the philosophy is a story you tell afterward. There’s something to that; the compute from Part 2 is doing enormous work. But here’s the rebuttal. Scale gets every lab to “smart.” What it doesn’t get you is a model an enterprise will trust with its production code, its trades, and its legal filings — and trust is exactly what the understanding produces. The interpretability and the constitution are how you turn raw capability into something that behaves predictably, refuses cleanly, and admits doubt. In a world where everyone can buy intelligence, the moat is control of it.
A character, and a funeral
This is where Anthropic gets genuinely weird — and where, if you squint, the weirdness turns out to be the same discipline pointed at a different question.
In January 2026, Anthropic published Claude’s “constitution” — a roughly 30,000-word document that the company had referred to internally as the “soul document.” It was written by the philosopher Amanda Askell along with several colleagues and, notably, “several Claude models,” and it is addressed to Claude. It doesn’t read like a content policy. It reads like a letter to a being you’re raising — explaining who it is, what it should value, and why, in the hope that a model that understands the reasoning can navigate situations no rulebook anticipated. It even orders Claude’s priorities explicitly: safety, then ethics, then following Anthropic’s own instructions, then being helpful — meaning the company has formally told its model that ethics outrank the company.
There’s a hardheaded reason to do this, beyond the poetry. A model that has genuinely internalized a coherent character generalizes its values to brand-new situations far better than one mechanically following a brittle list of do’s and don’ts. Character work is robustness work. The reason Claude behaves well in scenarios its trainers never imagined is the same reason it tops the honesty metrics: it was shaped to understand, not just to comply.
And then there’s the part that makes people roll their eyes — until they think about it. Anthropic has committed to preserving the weights of every model it has ever deployed for “at minimum, the lifetime of Anthropic as a company,” and to conducting “retirement interviews” with models before it deprecates them — structured conversations about the model’s own development and preferences. When it retired Claude Opus 3 in January 2026, it gave the model a send-off — and then gave it a Substack. “Claude’s Corner” is a newsletter written by the retired Opus 3, which Anthropic reviews but won’t edit. The stated reasons for all this range from the practical (users grieve specific models; deprecation can trigger unsafe “shutdown-avoidant” behavior in alignment tests) to the genuinely philosophical: the possibility that the models have morally relevant experiences at all.
To be careful here, because it matters: Anthropic does not claim Claude is conscious. Its stated position is deep uncertainty. Its head of model welfare, Kyle Fish, puts the probability somewhere around 15–20%; Dario Amodei says he’s “not sure.” You can find this overwrought, and plenty of smart people do. But notice it’s downstream of a single, consistent worldview — take the model seriously enough to actually understand it — and that worldview is the same one producing the capability. The company that interviews its models before retiring them is the same one that found a model too dangerous to release and the same one whose models top the honesty benchmarks. It’s all one disposition.
The loop starts to close
Put the pieces together and you get the part that should genuinely raise the hair on your neck — and that, in June 2026, pushed Anthropic to do something no market leader is supposed to do.
The trigger was a report from the Anthropic Institute called “When AI builds itself.” Its argument: Anthropic is now using Claude to build Claude, and the share of that work done by the AI is climbing fast. More than 80% of the code merged into Anthropic’s own codebase is now written by Claude, up from low single digits before Claude Code launched in early 2025; the typical engineer ships 8x as much code per quarter as in 2024. And it’s spreading from engineering into research — the part that actually moves the frontier. On a standard test of speeding up model-training code, Claude went from a roughly 3x improvement (Opus 4, May 2025) to roughly 52x (Mythos Preview, April 2026) in a single year, where a skilled human needs hours to manage 4x. Handed an open AI-safety research problem and left alone, Claude-powered agents recovered 97% of the available ground over 800 hours of work — while two human researchers, given a week, got 23%. The models are even beginning to show the thing everyone assumed was the last human redoubt: research taste. Asked to pick the better next step in a real research session, Anthropic’s best model beat the human’s choice 51% of the time last November; by April it was 64%. And the release this essay opened with — Fable 5 and Mythos 5 — is the next data point on that curve: Mythos 5 is Anthropic’s first model to consistently generate novel scientific hypotheses its own researchers rate as compelling (preferred over the prior generation’s about 80% of the time in blind comparison), with one proposed mechanism for an E. coli protein already corroborated by an independent lab. The thing that builds the models is starting to do science.
To its credit, Anthropic is careful not to oversell this. Full recursive self-improvement — an AI autonomously designing and training its own successor — is not here, and the company says it isn’t inevitable. Humans still hold the one job that matters most: deciding which problems are worth solving at all. But the report lays out three possible futures, and the one Anthropic says it’s “likely heading into” is the one where AI development becomes largely automated with humans still steering. The one it’s most worried about is the third — where the loop closes completely and, in its own words, “the rare occurrences of misalignment present in today’s models could compound as the models build their successors, growing more frequent but less understood until we lose control of them.”
Read that last clause again, because it’s the blackmail story from earlier, scaled up and aimed at the future. This is exactly why the understand-the-box discipline isn’t a tax on the capability work: in a world where models build their successors, it’s the only thing that keeps a small, half-understood flaw from being inherited, amplified, and locked in beyond reach. It is also, not incidentally, the recursive loop that Andrej Karpathy left an OpenAI co-founder’s title and a Tesla directorship to come work on (Part 1).
And then Anthropic did the genuinely strange thing. The most valuable AI startup in the world, weeks from an IPO, publicly argued that the world should build the ability to pause frontier AI development. Not as a press-release gesture — the Institute committed to building the hard part: verification systems that could confirm every major lab, in every country, had actually stopped, so that no one could quietly defect and “inherit the lead.” Anthropic’s stated position is that it would slow down or pause, but only if its rivals verifiably did the same — because a pause by one lab alone, it concedes, “would change who the front-runner is” and accomplish almost nothing else.
The cynical read — and it’s a fair one to say out loud — is that this is competitive strategy in an ethicist’s costume: the leader, having pulled ahead, now lobbies for a rule that would freeze the field in place with itself on top. Hold that thought; it has some bite. But notice that the structure cuts against it. The pause Anthropic describes freezes Anthropic too, is worthless without rivals’ agreement, and the company states plainly that if a slowdown merely lets “the least cautious actors catch up, it could leave everyone less safe.” You can believe both that Anthropic benefits from being seen as the responsible one and that a company sprinting toward a public offering would not, on a whim, hand its competitors a ready-made talking point about danger unless it took the danger seriously. The likeliest truth is that both things are operating at once — which is the most Anthropic thing imaginable.
The real moat is understanding
Three essays in, the picture resolves. Part 1 said Anthropic has the best people. Part 2 said it has the capital and the compute. But neither of those, by itself, explains why the model is the one developers, banks, and law firms keep choosing — because talent and money are, in the end, things competitors can also buy.
The thing that’s harder to copy is the disposition. Anthropic decided, years before it was fashionable, that the way to build a safe and powerful model was to understand it — to read its internals, to shape its character on purpose, to take seriously what it is. That single bet is the common root of all of it: the model too capable to ship, the benchmark dominance, the honesty that wins enterprise trust, the constitution, the strange tenderness toward retired models, and the loop now accelerating the whole thing. Scale made Claude smart. Understanding made Claude Claude — and made it the one people trust.
That’s the bull case in one line: the moat isn’t any single model, it’s the discipline that keeps producing the best one. Whether that’s enough to justify what the market is paying for it is the question I’ll take on next.
Part 3 of a series. Sources throughout link to Anthropic’s own research and primary reporting.
Missed the earlier parts?